 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCommunityKG-RAG: Leveraging Community Structures in Knowledge Graphs for Advanced Retrieval-Augmented Generation in Fact-Checking
Aug 16, 2024Despite advancements in Large Language Models (LLMs) and Retrieval-Augmented Generation (RAG) systems, their effectiveness is often hindered by a lack of integration with entity relationships and community structures, limiting their ability to provide contextually rich and accurate information retrieval for fact-checking. We introduce CommunityKG-RAG (Community Knowledge Graph-Retrieval Augmented Generation), a novel zero-shot framework that integrates community structures within Knowledge Graphs (KGs) with RAG systems to enhance the fact-checking process. Capable of adapting to new domains and queries without additional training, CommunityKG-RAG utilizes the multi-hop nature of community structures within KGs to significantly improve the accuracy and relevance of information retrieval. Our experimental results demonstrate that CommunityKG-RAG outperforms traditional methods, representing a significant advancement in fact-checking by offering a robust, scalable, and efficient solution.
Anger Breeds Controversy: Analyzing Controversy and Emotions on Reddit
Dec 01, 2022Emotions play an important role in interpersonal interactions and social conflict, yet their function in the development of controversy and disagreement in online conversations has not been explored. To address this gap, we study controversy on Reddit, a popular network of online discussion forums. We collect discussions from a wide variety of topical forums and use emotion detection to recognize a range of emotions from text, including anger, fear, joy, admiration, etc. Our study has three main findings. First, controversial comments express more anger and less admiration, joy and optimism than non-controversial comments. Second, controversial comments affect emotions of downstream comments in a discussion, usually resulting in long-term increase in anger and a decrease in positive emotions, although the magnitude and direction of emotional change depends on the forum. Finally, we show that emotions help better predict which comments will become controversial. Understanding emotional dynamics of online discussions can help communities to better manage conversations.
Dataset of Propaganda Techniques of the State-Sponsored Information Operation of the People's Republic of China
Jun 14, 2021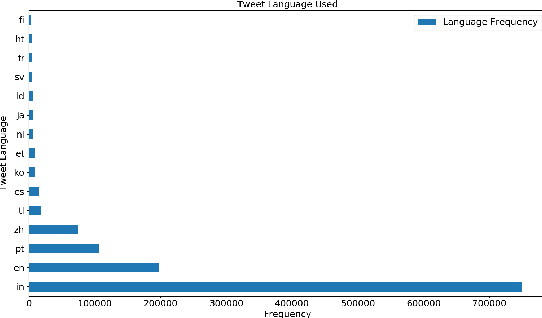

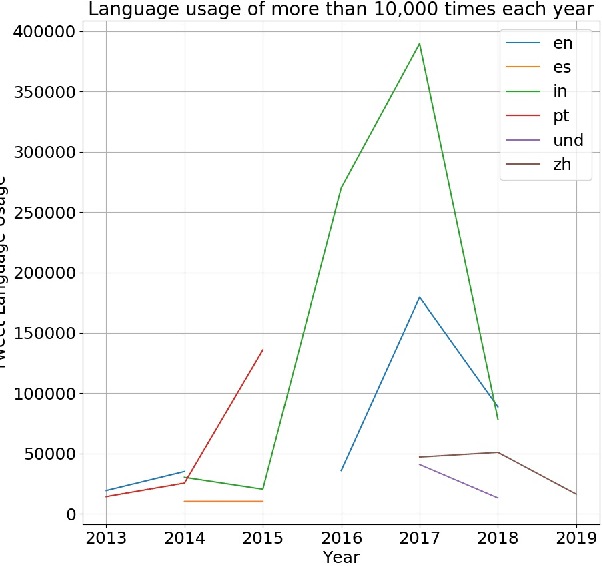

The digital media, identified as computational propaganda provides a pathway for propaganda to expand its reach without limit. State-backed propaganda aims to shape the audiences' cognition toward entities in favor of a certain political party or authority. Furthermore, it has become part of modern information warfare used in order to gain an advantage over opponents. Most of the current studies focus on using machine learning, quantitative, and qualitative methods to distinguish if a certain piece of information on social media is propaganda. Mainly conducted on English content, but very little research addresses Chinese Mandarin content. From propaganda detection, we want to go one step further to provide more fine-grained information on propaganda techniques that are applied. In this research, we aim to bridge the information gap by providing a multi-labeled propaganda techniques dataset in Mandarin based on a state-backed information operation dataset provided by Twitter. In addition to presenting the dataset, we apply a multi-label text classification using fine-tuned BERT. Potentially this could help future research in detecting state-backed propaganda online especially in a cross-lingual context and cross platforms identity consolidation.